![]()
How to implement BigQuery autoscaling reservation in 10 minutes?
Autoscaling in BigQuery offers a smart solution for managing query costs by adapting slot usage to your workload. Unlike On-Demand pricing, which charges based on data volume, autoscaling slot reservations allow billing based on actual slot time used. This guide will walk you through setting up BigQuery autoscaling reservations in just 10 minutes tops, helping you maximize efficiency and reduce costs effortlessly.
On-Demand VS Autoscaling Reservation
BigQuery's default On-Demand mode bills queries based on data scanned at $6.25 per terabyte, making large data scans costly and small ones cheaper, regardless of query duration. Autoscaling reservations offer an alternative, billing based on slot time used ($0.04 - $0.06 slot hour). In this model, you pay for reserved capacity continuously, so maximizing usage by filling the reservation with as many queries as possible is crucial for cost-efficiency. Deciding for each query between On-Demand and autoscaling can be complex, this is where Biq Blue comes in, telling you which project to pick to optimize your queries as much as possible.
Is it worth it in $$$? 2min
To find out, it's very simple: go to Biq Blue, select the Savings analysis, and you'll see the potential savings on slot reservations.
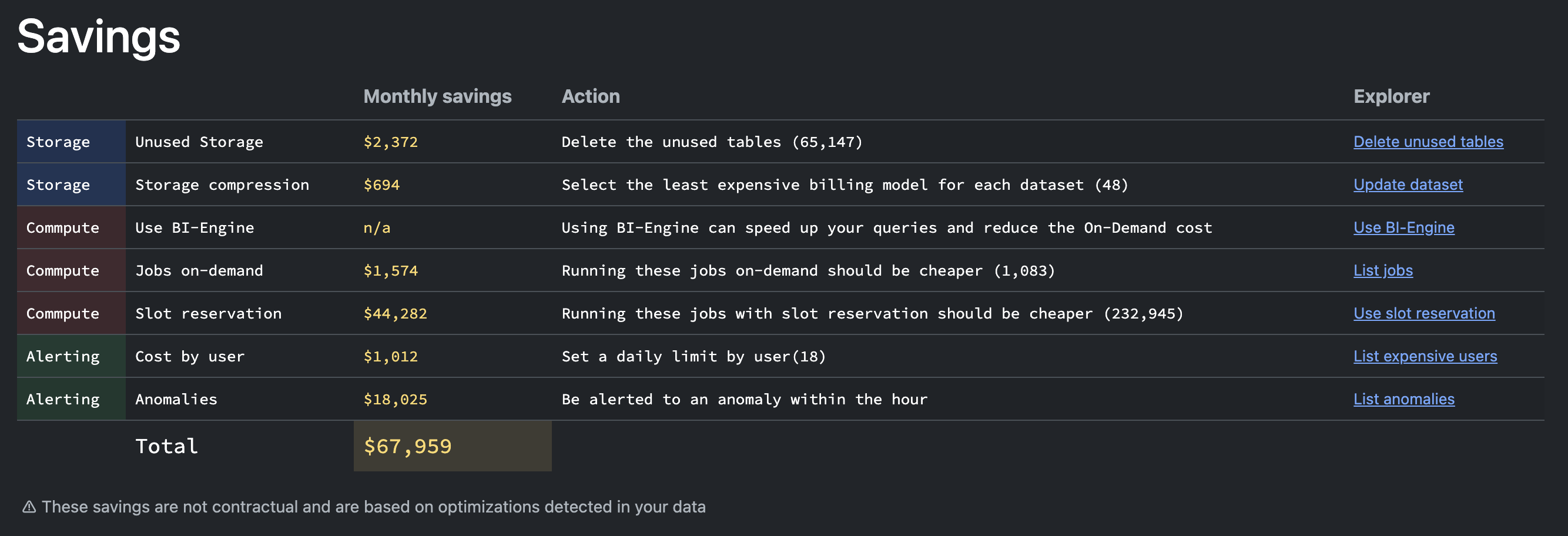
Then, click the link and continue until you display the chart showing On-Demand queries that would be cheaper using slot reservation, broken down by project.

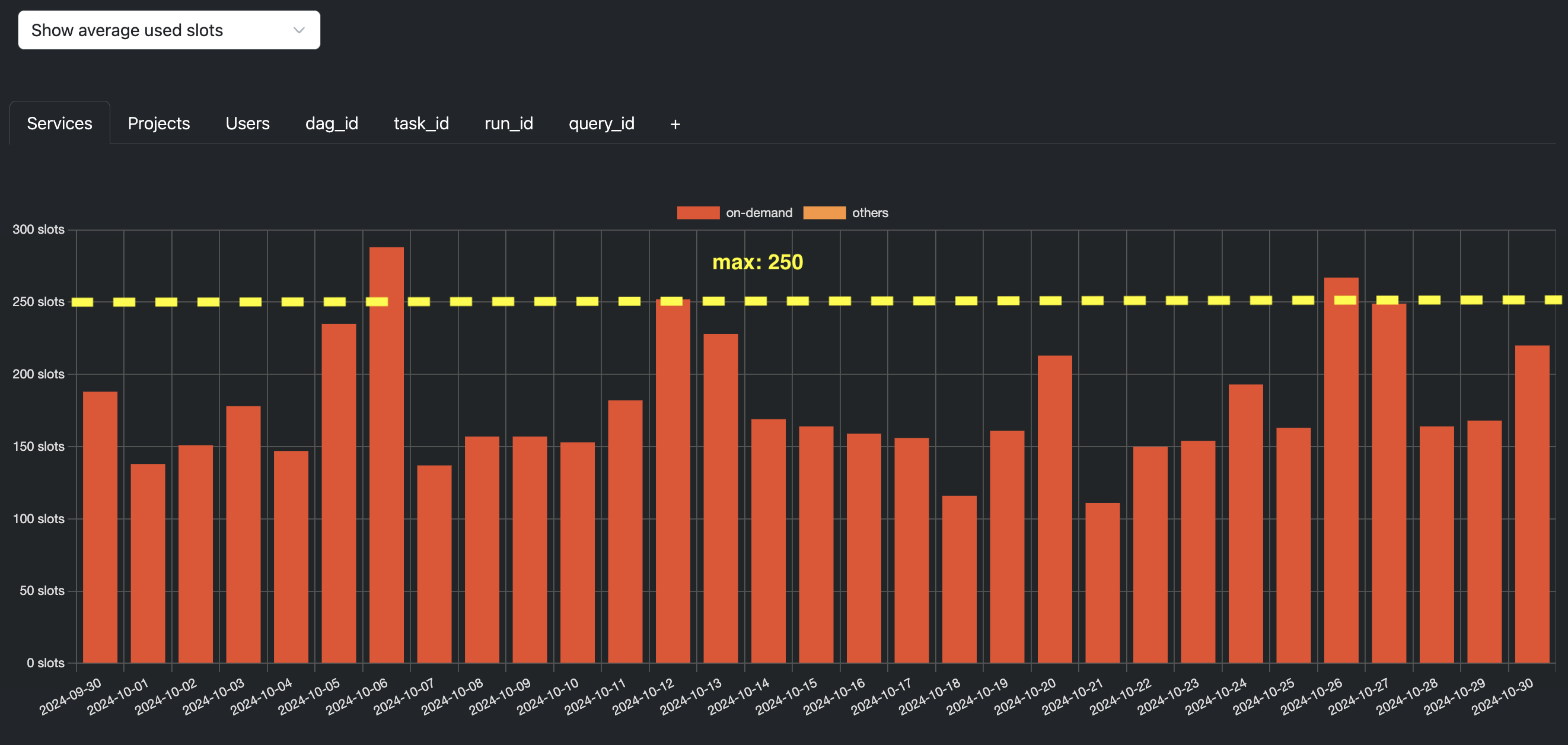
Use the tabs and filters to pinpoint the ideal project for implementing autoscaling reservations: select the one with the highest savings potential!
❗ Autoscaling project increments slots by 50, so if your workload is too far from this minimum value, you should probably not implement autoscaling slots.
Create an autoscaling reservation 3min
Now that you know which service to start with, create a new project in GCP. Access the console and set up a new project named something like my-autoscaling-project.
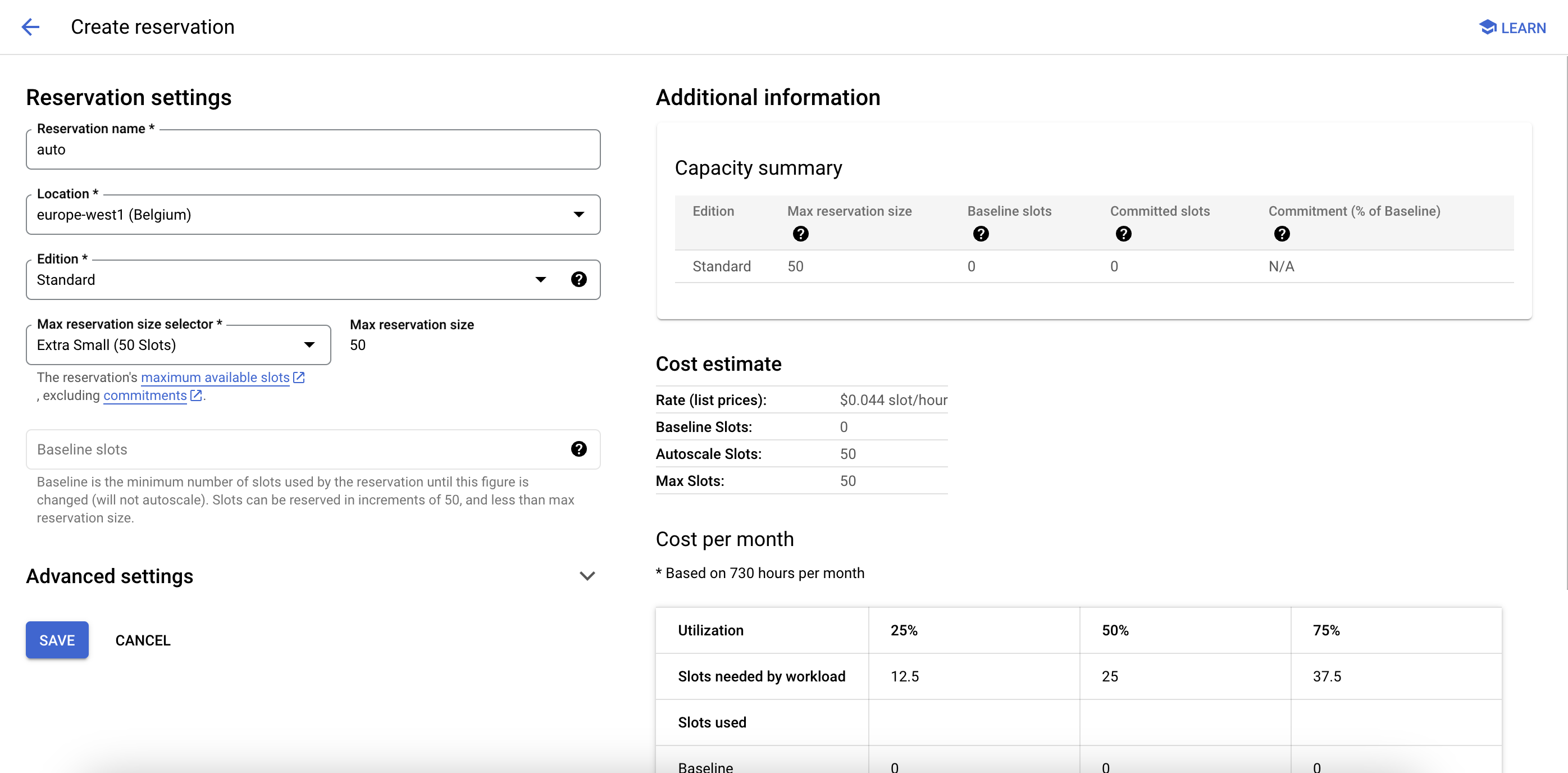
Next, create a new reservation here. Select your region, then set the baseline to 0 and use your previous estimate for the max.
Now, click on the action button, and select "Create assignment", select "my-autoscaling-project".
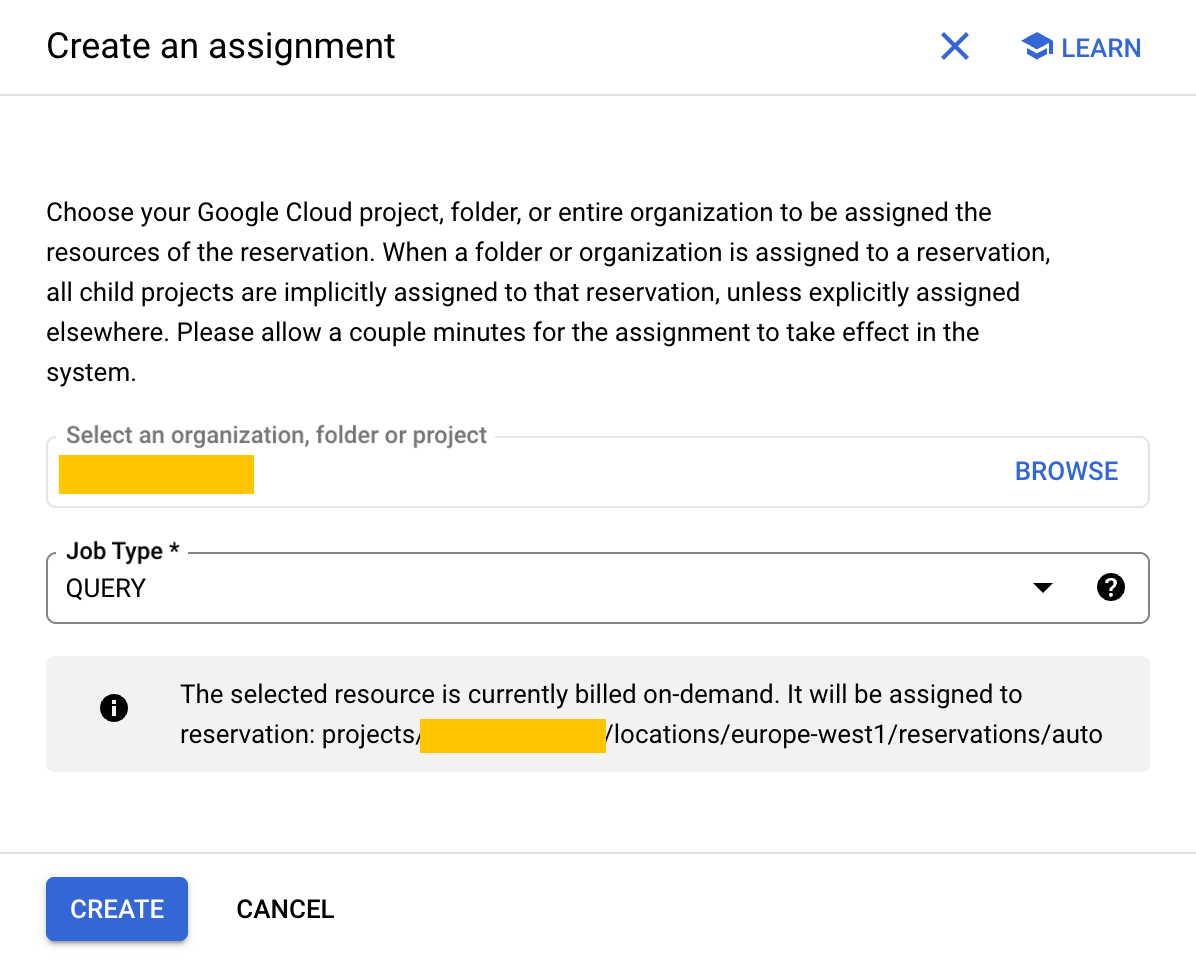
❤️ Don't worry, with a 0 baseline, the reservation will cost $0 as long as you don't send a query to it.
Implement Pick API 5min
Now it's time to decide which query should run On-Demand and which should go into the reservation. We've developed an API to help you determine this: the first time a query goes through Pick, it will default to On-Demand. The second time, the API will use the result from the previous run to recommend either On-Demand or Reservation.
1 - Get your apikey in Biq Blue
Click on your profile picture in top right corner / Your plan / apikey is in the developer section, at the bottom of the settings.

2 - Clone our examples on GitHub
Choose your favorite flavor: Javascript, Typescript and Python.
3 - Follow the README
First, modify the query.sql: go to Biq Blue and select a query that should be cheaper in a slot reservation project. Copy the SQL and paste it in the query.sql file.
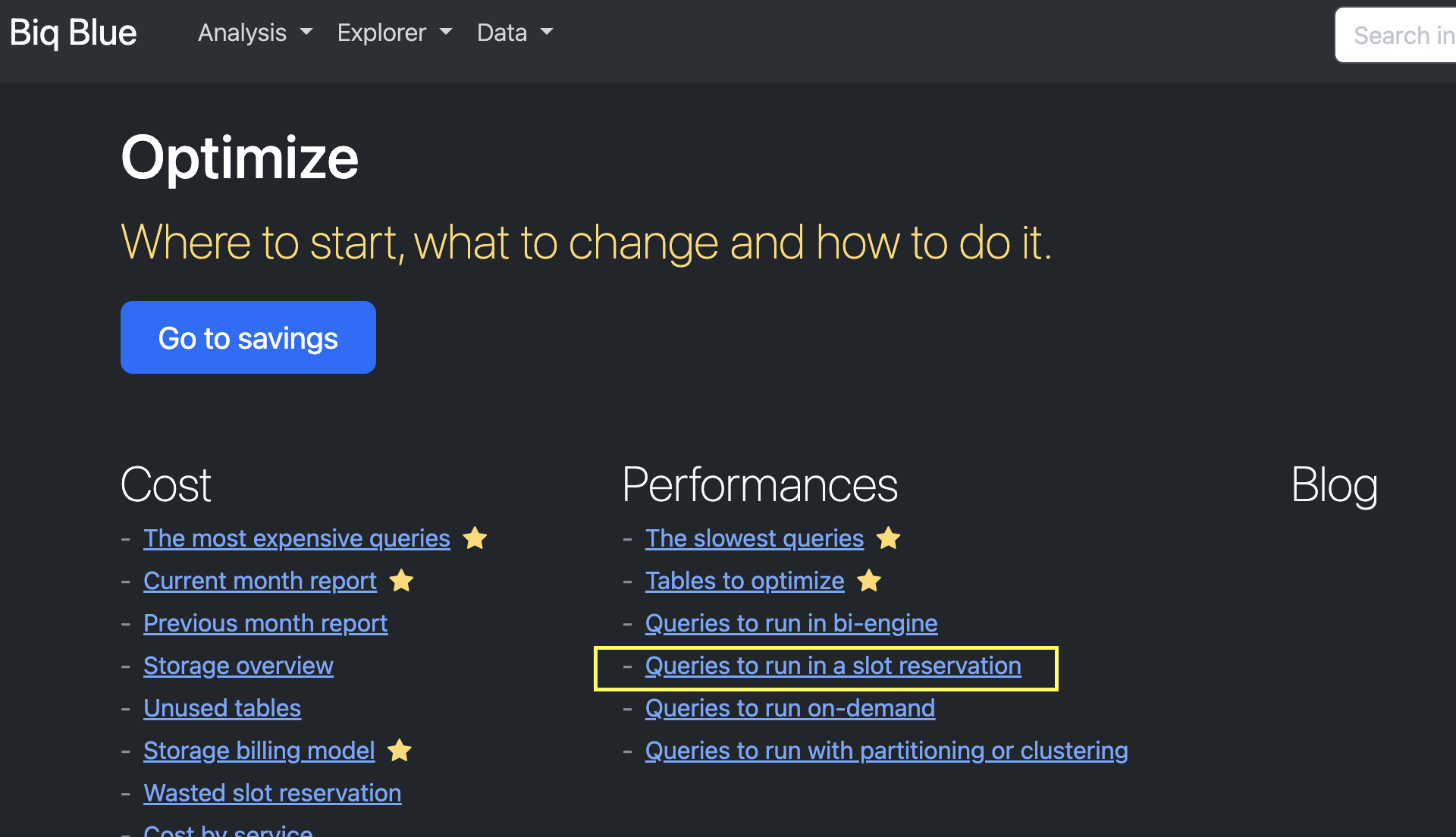
Then, install the dependencies and create the .ENV file with:
- Your
apikey - Two service-accounts: one from the On-Demand project and one from the Autoscaling project (they both need to have permissions to run this query)
- Your region (us, eu, europe-west1, etc)
The first time you run it, the query will be On-Demand. The second time, the API will recommend a Reservation if it's cheaper. In only 10 min you have run your first query in an autoscaling project, bravo! 🤩
Check the slot usage in Cloud Monitoring.
Now implement Pick API in your projects
Reproduce the example mechanism in your projects (adapt according to the language you use):
- Add
pick.jsfile to your project - Use
pick.getFromQuery(query)to choose which project should run this query - Run the query, then
pick.updateFromQuery(query, job)to keep Pick API up to date
If you take a look at pick.js, you can see that we simply generate a hash from the query, so the first time this query runs, Pick API will respond to use On-Demand project. The second time, this same query may recommend to use the autoscaling project.
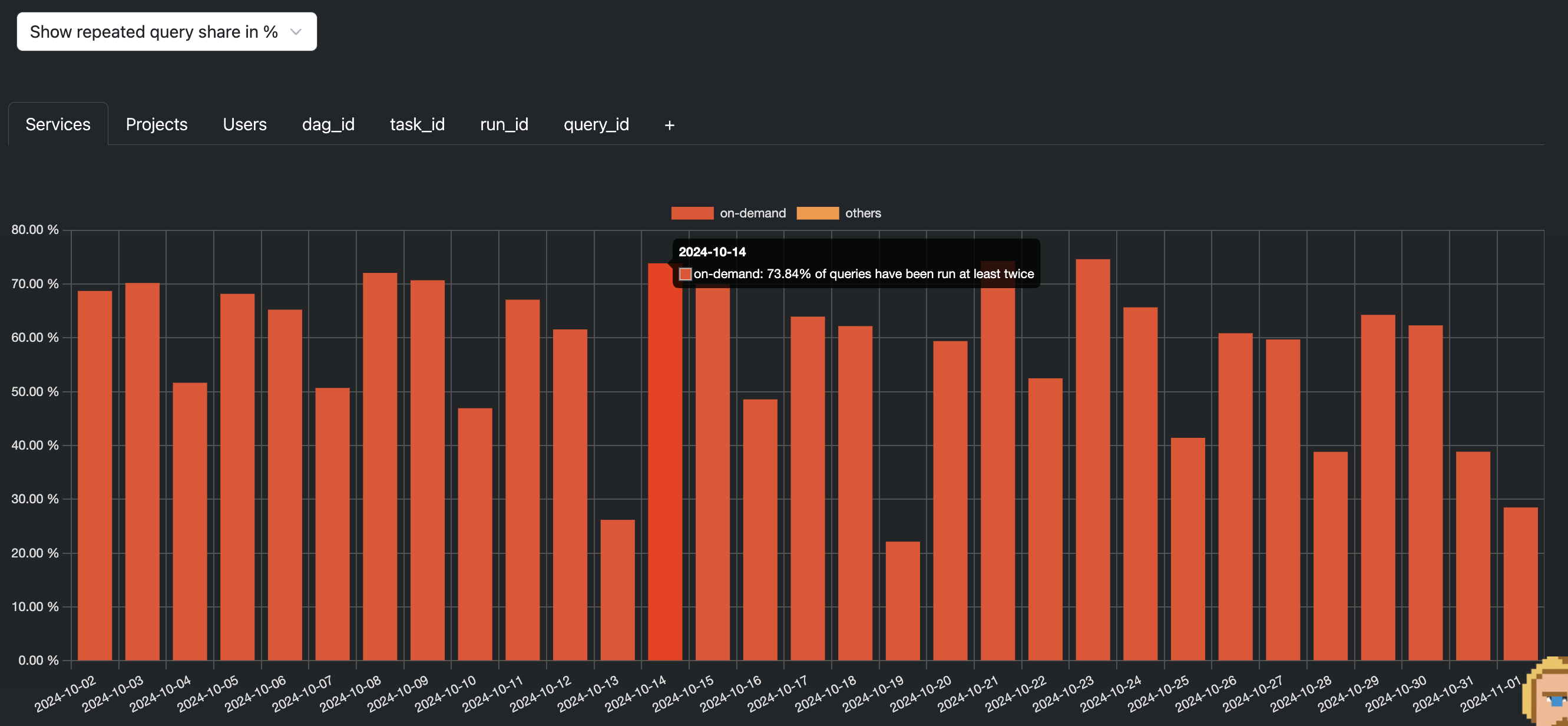
This mechanism is very useful to handle automatically a lot of queries in your projects. You can see how many queries are executed in BigQuery at least twice by going to the Jobs Analysis, "Show repeated query share in %"".
Optionnal - Generate the hash yourself
The automatic hash is a very convenient way if your workload is working with queries that are litteraly the same. But how to leverage Pick API when your queries are templated?
SELECT * FROM `my-table` WHERE category_id = %A_CATEGORY%;
At runtime, this query could always have a different hash, even if you think that they should be the same.
💪 Use your own hash
The file pick.js provides 2 functions like the previous ones, but instead of using the final query, you use a hash that you generate yourself. For example, from the templated query.
pick.getFromHash(hash)pick.updateFromHash(hash, job)
❗ Be sure that the queries can be considered the same.
What next?
Now that you've redirected part of your workload on autoscaling, there are 2 things to check:
- Have you saved any $?
- Doesn't your workload slow down?
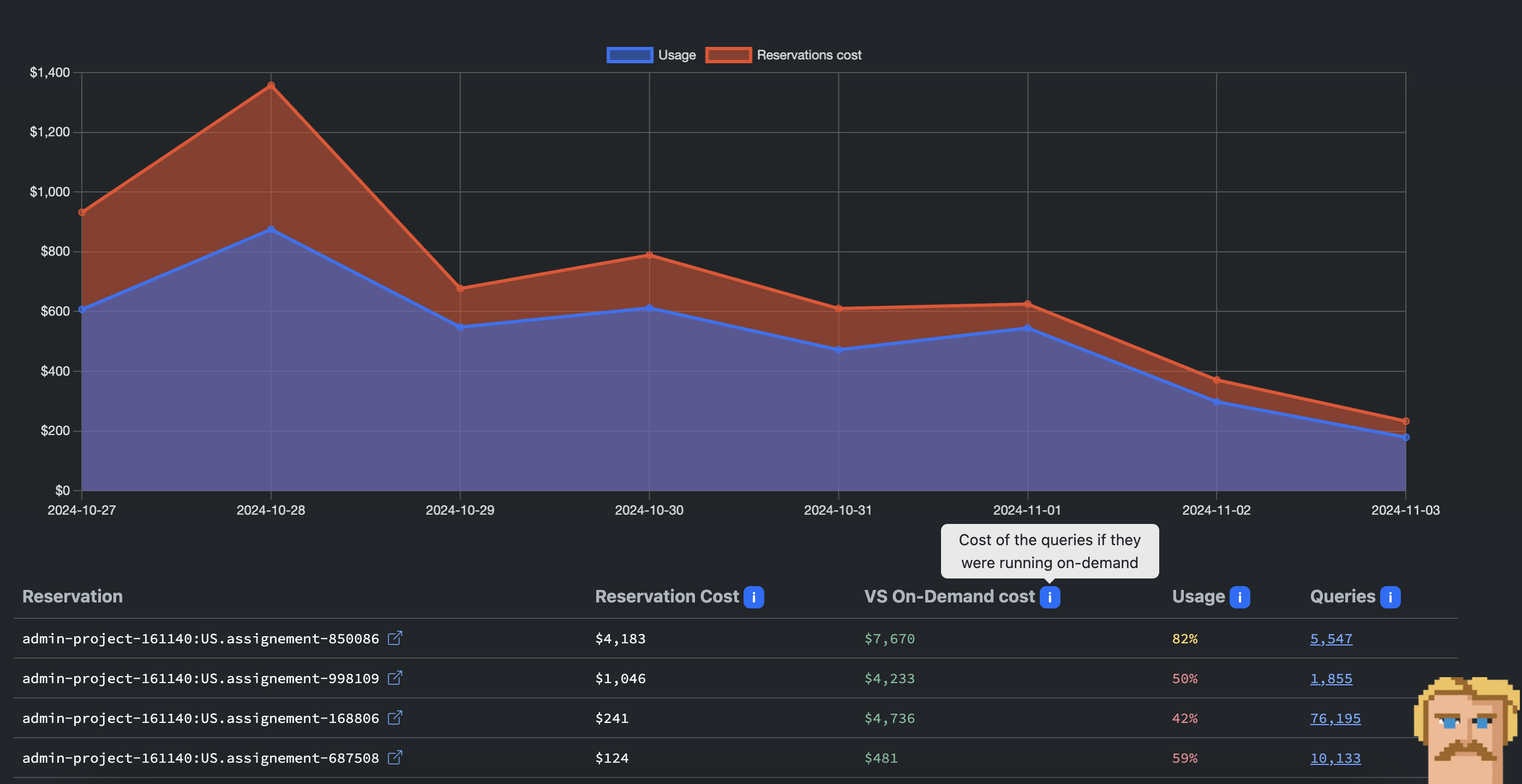
Biq Blue makes it easy to find the answers. Go to the Reservations Analysis to check the efficiency and gain of your reservation. You'll see the cost of the Reservation VERSUS the cost of On-Demand queries.
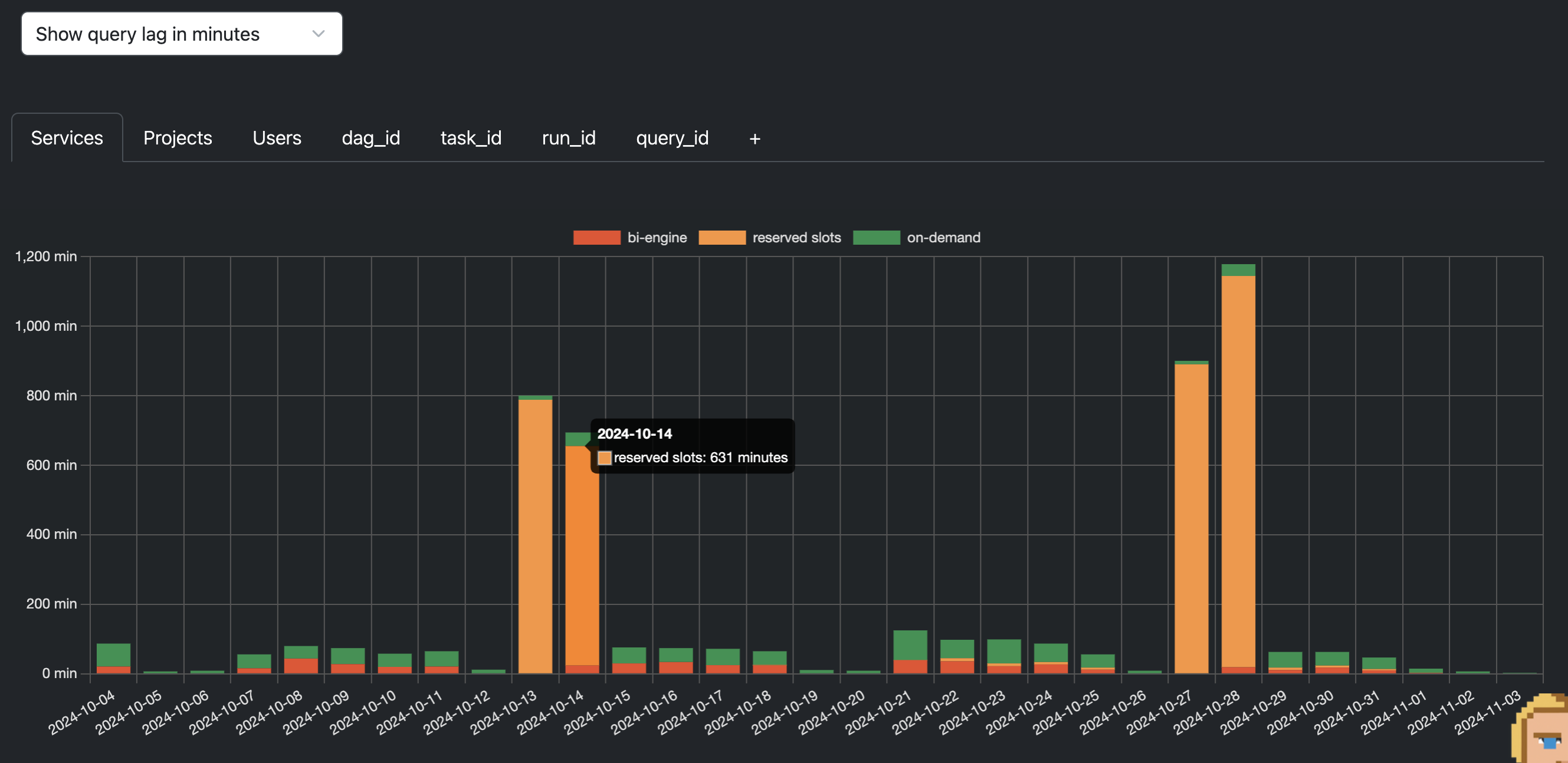
Another important point: even if it's cheaper, you need to keep the same velocity. Go to the Jobs Analysis and click on “Show query lag in minutes”. If your workload starts to run out of slots, you'll be able to see this and consider increasing the maximum number of slots in the autoscaling reservation. And if you have Slack plugged in, you'll receive an alert within an hour of your workload slowing down.
Conclusion
Setting up autoscaling reservations in BigQuery is a quick and effective way to optimize your data processing costs. By dynamically adjusting slot usage based on workload demand, you can balance performance with budget constraints, making your data operations more efficient and scalable. Implementing this approach not only saves on costs but also provides flexibility as your data needs grow. With this simple setup, you're ready to make the most of BigQuery's capabilities while keeping expenses under control.